

Last week, I got the chance to play around with Anthropic’s highly anticipated model: Fable 5.
For those who haven't followed the development of frontier models (like ChatGPT or Claude), the short version of the story is that it was reported to have capabilities so dangerous that the public couldn't have access to it. So, imagine that the AI was so good at finding security vulnerabilities that critical infrastructure could be at risk by giving the public access to it. As expected, this resulted in a long tail of people speculating as to what could be behind the gated model.
After much anticipation, Anthropic released a public version of Mythos called Fable 5 last Tuesday, June 9th. As someone who has a Max plan, naturally I had to give it a spin.
First Impressions of Fable 5
Honestly, contrary to all the hype that social media wants you to believe in, I thought it was good, but it didn't blow me away (in the time I had with it).
Research / Discussion
The first thing I did with Fable 5 was test out its reasoning and comprehension. Here's an example where I wanted to test its ability to discuss the technical feasibility of a token tracker app I was considering building as a side project:
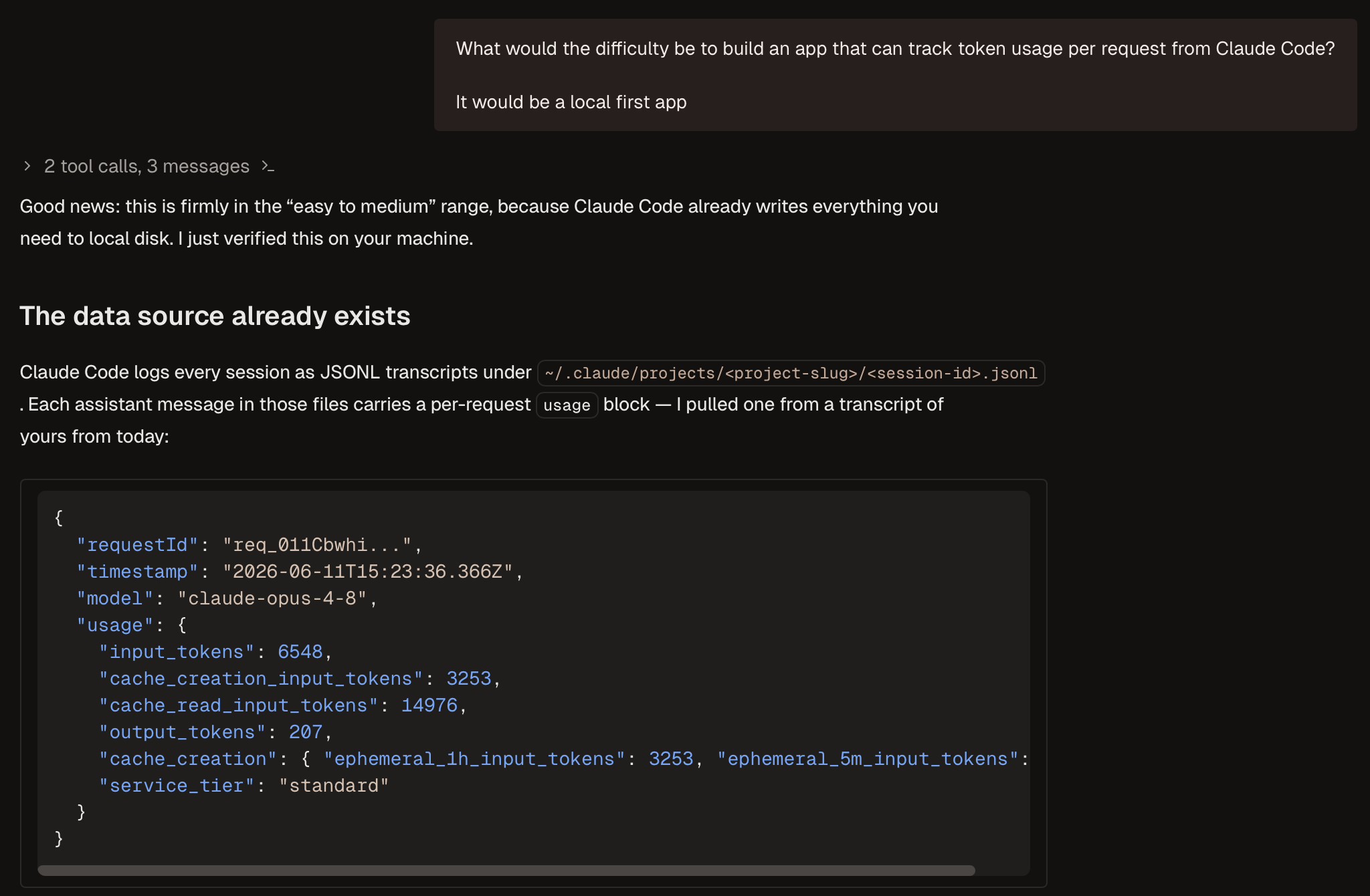
The details aren't important, but what I can say is that it was well-reasoned and helpful. It taught me some things about how there are local logs that contain metadata I could use for the app which was great. But in comparison with Opus 4.8 (1M Context), it didn't do anything so drastically different.
Granted, while this example wasn't the most complex of questions, my general impression was that it was fairly consistent in helpful responses, but there wasn't anything particular that was mind-blowing about it.
Coding Tasks
Now of course, there is always the question of how it performed on more complex coding tasks. While I could not capture that in a screenshot, once again it was good, but it wasn't perfect and still made mistakes / odd decisions.
For example, I had it go through and do a large CSS refactor across the entire codebase, but when it finished the work for me to review, I could clearly see that it had chosen to create some global classes that made much more sense to be scoped component styles instead.
Large Task Requests
Part of the big claim of Fable 5 is that it's able to take a large complex task and then reason its way into a viable solution. And while there have been claims online of people being able to churn through massive code refactoring / "one-shotting" (i.e., building it in one request) a complex app they always wanted to build, I personally did not experiment with this because:
- Fable 5 used a LOT of tokens. This wasn't necessarily a surprise, but I could clearly see my token usage ticking up despite the fact that they were fairly scoped questions. One could make the case that I shouldn't have been using Fable 5 for that type of task, but that's a discussion for another time.
- I didn't have time to evaluate the work properly. Engineers already dread the multi-file PR that touches on thousands of lines of code, so why would it make sense to voluntarily opt-in to that scenario when I have other work to do?
- It focuses on the wrong thing. While it's cool that it can reason through complex problems at a higher success rate than before, I'm of the stance that the best use of AI is helping me to grow as an individual. Productivity for the sake of productivity is dangerous especially if you can't maintain quality control.
Initial verdict?
While I didn't experience any mind-blowing gains in performance, if I were purely evaluating the model compared to what I have access to, Fable 5 would certainly be my model of choice. That said...
In case you didn't know, the US government decided to suspend access to Fable 5 last Friday, June 12th, 2026. So while I only had three days with the model, I remain curious as to whether the gains of the model are worth the true cost of the model. While the benchmarks may show improvements up to 10% improvement on the agentic coding benchmark from Opus 4.8, is that 10% worth the added token cost? Especially when you have to consider the fact that it's not as if the work is perfectly done and requires no additional effort?
At the end of the day, what we all have to remember is that we (as the consumer) are still not sure how the true cost of enterprise AI models will land. And if even Microsoft is concerned about AI costs, I can assure you that the rest of us do not have the budget to just burn through tokens.
That's not to say that we shouldn't take the time to leverage this era of subsidized tokens to learn and explore the capability of what frontier AI models with massive compute are capable of, but we must remain vigilant as to the real world implications when making decisions for our teams and/or businesses.

